Algorithmic Operations: Lessons from Bandit Algorithms
Posted: Updated:
Algorithmic Operations: the maximal use of algorithms to make essential business decisions.
The practice can be traced to the hedge fund industry. The operations of ingesting data to predict prices and execute trades is a friendly environment to algorithms, which are constrained to act only via programmatic interfaces. By the mid 1990’s, the early-digitized financial markets produced decisive proof of algorithms’ efficacy in the form of the unprecedented success of quantitative hedge funds like Renaissance Technologies and D. E. Shaw. Its influence spread, with one path traceable from D. E. Shaw, when Jeff Bezos, a freshly indoctrinated algorithm evangelist, left the company to start Amazon in 1994.
However, the retail business lacked programmatic access. In the late 1990’s, ordering from wholesalers, tracking shipments, directing inventory, packaging items, and shipping orders were frequently done manually. Ordering from wholesalers often involved phone calls or faxed purchase orders, tracking shipments relied on manually updated spreadsheets or physical ledgers, inventory management required store managers to walk through aisles with clipboards, and packaging and shipping orders depended on workers assembling boxes with printed labels based on handwritten instructions. To direct these operations digitally would require new technology throughout the entire supply chain. Over the following three decades, Amazon performed this transformation with enormous effort and contributed1 to a growing industry philosophy of algorithmic essentialism.
Today, entire industries, like ridesharing, depend sensitively on effective algorithmic operations and any declaration of its value reads as a cliché. Yet, they remain the exception rather than the norm. Recognizing colloquialisms like ‘Excel Hell’, ‘Email Ping-Pong’ and ‘Death by Meeting’ is all one needs to appreciate this fact. The answer to ‘why?’ is ‘because it is hard’. This article seeks to explore this more thoroughly.
More constructively, this article is to provide clarity on the causes and make informed recommendations for progress. In total, this is an article about automated decisioning.
Our approach is to compare a company’s algorithmic operations to those of fully programmatic learning algorithms. The analogy contextualizes problems and clarifies requirements. Further, in our recommendations, we cite time-tested, nonspeculative solutions.
This article is informed by the authors’ combined 8 years of experience at Lyft, a review of 14 Amazon employee interviews, comments from other industry practitioners, and a survey of literature, including 12 MLOps papers and nearly 100 blogs from Lyft, Uber, Instacart, DoorDash and Airbnb. We focus on these companies because they have been successful in algorithmic operations and are local to our experience.
Algo Ops: What It Is
Repeating the definition, Algorithmic Operations (‘Algo Ops’) refer to the maximal use of algorithms to make essential business decisions. The term ‘maximal’ is used as an alternative to ‘exclusive’, since no organization exclusively uses algorithms for decisions. This is to suggest ‘getting algorithms to do everything they can and should do.’
Algo Ops are different from algorithmic products. Algo Ops are about automating the internal machinery of a company, while algorithmic products are about delivering value to users through algorithm-driven features. Google Search’s decision of which websites to return most directly benefits the user. Uber’s dynamic pricing system is designed for revenue and profitability. Both rely on algorithms, but their context, intent and beneficiaries set them apart. These differences create distinct desiderata and challenges.
Algo Ops are different from Machine Learning Operations (‘MLOps’), though they heavily overlap. Indeed, much of our literature review was from MLOps. However, while MLOps focuses on the development lifecycle of ML models2, Algo Ops encompasses the broader application of algorithms to automate and optimize decision making across the entire business. MLOps is a critical component of Algo Ops, but not all algorithms involved in business operations are ML models. For example, data-less rule-based systems, optimization algorithms, and other non-ML methods are integral parts of Algo Ops. Revealing the term’s breadth, Algo Ops subsumes much of operations research in addition to MLOps.
We’ll also define partial Algo Ops, or Algo Ops designed with ‘humans-in-the-loop.’ Partial Algo Ops, for many categories of decisions, are best practices. An example is the the entire scientific discipline of commercial experimentation, whereby control and treatments groups are deployed, logged and analyzed to inform a person’s go/no-go decision. Partial Algo Ops are accepted as the final destination, since many questions cannot be raised and answered by algorithms alone, like some system-level engineering decisions or UI design choices. Other motivations are for transparency and well defined accountability. Further, they may benefit when difficult-to-measure economic trade-offs are involved, and can only be properly balanced with domain experts. In other cases, partial Algo Ops are considered an intermediate step on the way to Algo Ops; humans are there to ‘fill in the gaps’.
Deploy, Explore, Log, Learn
In pursuit of Algo Ops, we will consistently reference a framework described in the 2017 Microsoft Research paper “Making Contextual Decisions with Low Technical Debt.” Agarwal et al. (2017) was partially a response to the well known 2015 Google paper “Hidden Technical Debt in Machine Learning Systems,” which explained the pernicious causes underneath the expensive and deleterious process of large scale machine learning model maintenance. Agarwal et al. (2017) explains the ‘Deploy, Explore, Log, Learn’ framework (“DELL” as only we will call it) in their presentation of their ‘Decision Service’, a product enabling applications of contextual bandit (CB) algorithms and addressing challenges described in Sculley et al. (2015).
Bandit algorithms are of particular interest because they perform the complete loop of automated decisioning, including observing, deciding and learning. They are dedicated to the expansive class of causal modeling, which encapsulates predictive modeling3. Indeed, bandit algorithms are attractive for this completeness, but such completeness brings the full set of technical issues. The paper’s approach to this broad class of challenges is what makes it relevant for our purposes.
Agarwal et al. (2017) present DELL as a software abstraction designed to capture a wide range of automated decisioning applications. More technically, they recognize that any CB system’s data is be made up of, implicitly or explicitly, many tuples described as follows:
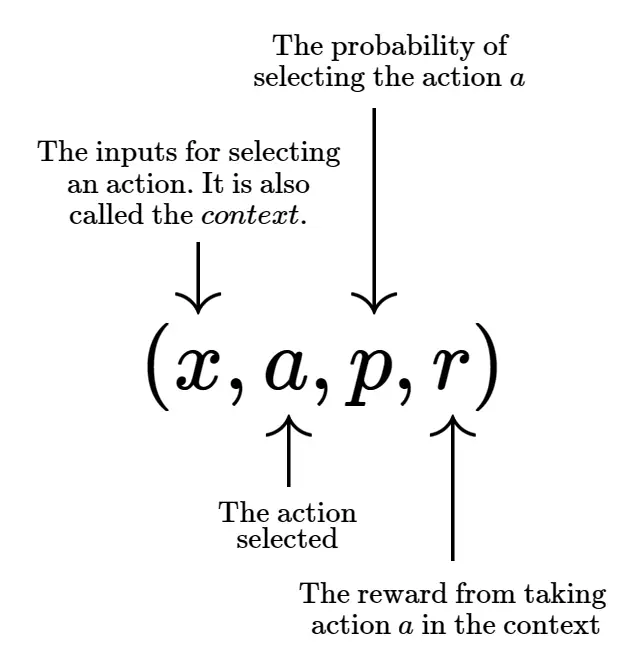 Contextual bandits are trained on tuples of four pieces of data.
Contextual bandits are trained on tuples of four pieces of data.
The challenge is maintaining the consistency and integrity of these tuples. This is challenging since they are often generated across widely separate business functions. The DELL abstraction is to provide decisioning flexibility, and their software is to guarantee the quality of these tuples and the models developed on top of them.
Our observation is that this framework must operate for any Algo Ops system, even those involving humans. Any such systems should know the context of its decisions, the decisions themselves, the associated probabilities and the rewards. Doing so is necessary for it to improve via data. In what follows, we will apply this perspective as a lens to contextualize problems and recommend solutions. Before that, we describe the component operations:
The components are operations, to be executed repeatedly and in circular fashion by an Algo Ops system:
- Explore: In addition to effective actions, exploratory actions must be made to generate informative data.
- Log: Correctly store observations of all relevant variables, from exogenous inputs, to model internals, to target variables.
- Learn: Update the model according to observations and feedback.
- Deploy: Deploy the updated model into the environment.
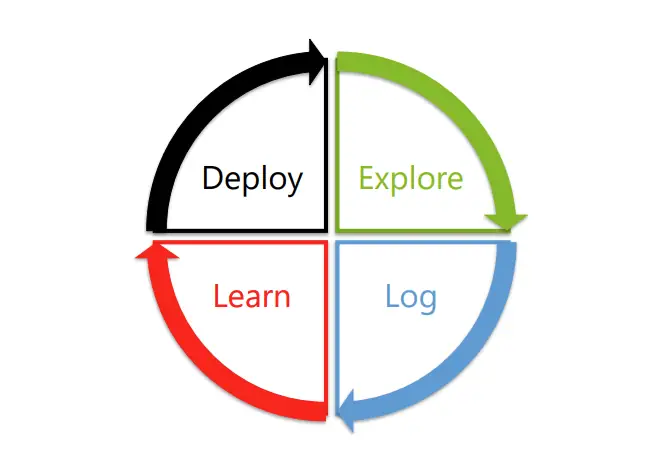 The four required, synchronized operations of an adaptive decision system. Image source: Agarwal et al. (2017)
The four required, synchronized operations of an adaptive decision system. Image source: Agarwal et al. (2017)
We find this perspective informative for several reasons. First, naming the components and declaring that each must be done well is a useful exercise for all contributors; each are frequently neglected by one group or another, yet they are all requirements. For example, experimentation is frequently deprioritized due to its expense and abstract value, despite its typical necessity.
Second, the components must be developed in code-level and organization-level coordination with each other, and this, in our review, is a cavernous source of problems. Components are frequently managed by independent processes spread across teams, preventing coordination with anything more reliable than conversation. The model destroying misalignment of production and development environments is a notorious symptom.
Third, the system improves with each complete cycle through the components, so any frictions or disruptions can be identified as interfering with that overall goal. For instance, delayed decisioning feedback expands the time between Explore and Learn, slowing iteration cycles. Manual deployment procedures, slow experimental design processes, unreliable ETL jobs and ad-hoc model tuning are other procedural pathologies that slow DELL cycles.
DELL System Development
To organize technical challenges, we will sequence them similarly to how they might be encountered while building from scratch. To do that, we provide a simple building procedure. We assume the following is done with the necessary infrastructure in place. To clarify, these are not the DELL actions. DELL actions are what the system must do once it is functioning properly. Rather, these are steps to develop a minimal procedure that performs DELL. Since human-in-the-loop Algo Ops is the norm, so is this procedure.
-
Gather initial data: This typically involves writing code to generate and save a dataset. It is expected this data can be regenerated on an ongoing basis, is structured in a way a model can ingest and contains the necessary information for the model to perform well. Assuming it is a causal model, some experimental data should be included.
-
Develop and evaluate the model: The model is built and iterated on until some holdout evaluation is satisfactory. As much as possible, the evaluation metrics should be representative of the broadest intent of the model.
-
Develop data serving: For the model to operate in a live environment, data identically defined to that used for offline model development must be made available in the online live environment. This step is to build the required pipelines. The ‘identically defined’ requirement necessitates a variety of data quality checks.
-
Develop model deployment procedure: Code is written that trains the model on regularly refreshed data. Often, a serialization procedure is written to export the model in a standardized format and serve it to a live environment, though there are alternative approaches.
-
Develop model logging and observability: Pipelines are developed to record the served model’s context, inputs, intermediate values and outputs. These are logged for evaluation purposes and to accrue future training data. Also, analytics are built to create visibility and assist future decisions about fixing or improve the system.
-
Deploy model: Execute the deployment procedure, which trains and moves the model into production. Beyond what is required to do this, it may also involve inspecting data quality checks, running unit and integration tests, manually reviewing the serialized model, data analysis of recently served data and crossing fingers.
-
Monitor live performance, gather feedback, update processes developed in steps 2-5 and return to step 6: For many reasons, some avoidable and some not, live data is likely to reveal problems. It may suggest the model is not fulfilling its goal or is deviating from expectations made in step 2. Observations and hypotheses should be written down, turned into recommendations, prioritized and executed. With those updates, a new model is ready for deployment.
This relates to the DELL framework as follows. ‘Deploy’ is performed with steps 4 and 6. ‘Log’ is performed with steps 5 and 7.
‘Explore’ is done on two levels. The model itself is responsible for taking exploratory actions. In this sense, Explore is a requirement of the model and should be captured in step 2. On a higher level, exploration is done in step 7 and by those developing the system. Broadly, exploration is about generating observations which inform future improvements, and in this sense, both the algorithms and contributors participate.
‘Learning’ is similarly done on two level. Learning is the translation of new information into system improvements. That may be done by retraining the model on fresh data or updating the system based on live monitoring feedback.
Challenges
A small team applying these steps to a modest problem may not encounter any technical difficulties outside of modeling questions. They arise when the system ingests large and diverse data, involves multiple teams, utilizes distributed computing and storage, is written in multiple programming languages, requires long configuration files, creates sprawling dependencies, contains many pipelines, glues infrastructure, demands vigilance, and faces dynamic real-world conditions. In our analysis, these effects dislocate DELL operations and complicate them individually, slowing or stopping feedback.
In this section, we focus on challenges which are informed by the DELL perspective. This mostly omits engineering questions that are common to any large scale system and not necessarily a decisioning one.
Challenge: Modeling and Biased Data
Modeling challenges are those addressed in textbooks on statistics, optimization, machine learning or simulation. Generally, they concern the process of turning observations into algorithmic updates. In this sense, they are of the ‘Learn’ components. However, modeling challenges also arise in the design of exploratory actions, and in this sense, they are a component of Explore.
Modeling challenges can normally be well expressed as mathematical problems and have mature software solutions. For this reason, outside of this section, we will abstract away the modeling problem as the task of using observational and exploratory data to make predictions and decisions4. The post Why is machine learning ‘hard’? explains some of what we are skipping here.
We make one important note on a ubiquitous issue concerning the interaction of learning and exploratory. Decisioning system often generate their future training data, creating a strong possibility of biased data. Recommender systems, which decide which items to show customers, are informed by historical transactions. However, once the recommender is deployed, it will influence those transactions, partially invalidating them for evaluating a future recommender. This is a well appreciated problem for recommenders (see Zangerle (2022)), but not specific to them, as discussed in Sculley et al. (2015). The only proper solution is sufficient randomized exploration, a la bandit algorithms.
Challenge: Code, Data and Metadata Misalignment
The challenge of steps 1-7 and updating previous work with feedback is strong path dependency. Step 2 depends on the details of step 1. Step 3 depends on steps 1 and 2, and so on. In the worst case, every step could depend on every previous step, including the ongoing feedback iterations. However, engineering best practices intends to create abstractions which simplify dependencies, so operations may be considered independently. Unfortunately, as pointed out by Zheng (2014) and labeled ‘Abstraction Debt’ by Sculley et al. (2015), there is a lack of solid, time-tested interfaces for data streams, pipelines, models or outputs.
The result is misalignment. Contributors, by the limits of time and attention, either treat dependent components independently or must use weak alignment mechanisms, like meetings.
Next, we describe common symptoms and causes.
Misalignment of model development and live environments
A typical disconnect is between the data used for model development and the data it encounters in production. Data scientists often build models using static, personally-curated datasets (as in steps 1 and 2) that are readily available in development environments. However, once deployed, these models receive data from pipelines built by data engineers and often with different definitions, transformations, and latency.
A common culprit, but technically an orthogonal issue, is the difference between batch and streaming data pipelines, which process data at different cadences and with varying levels of granularity. In a batch pipeline, data is processed at regular intervals, allowing for heavier transformations and joins. In contrast, streaming pipelines handle real-time data with lower latency and may lack the same compute budget.
Contributors will normally check for these differences, but those checks are not guarantees. Data scientists and engineers may verbally agree they are equivalently transforming the same upstream data, but this is an unreliable process that must be repeated on every model deployment, slowing DELL cycles and blocking feedback.
The separate pipelines and the additional proactive effort to align them is made clear with a figure from Polyzotis (2017).
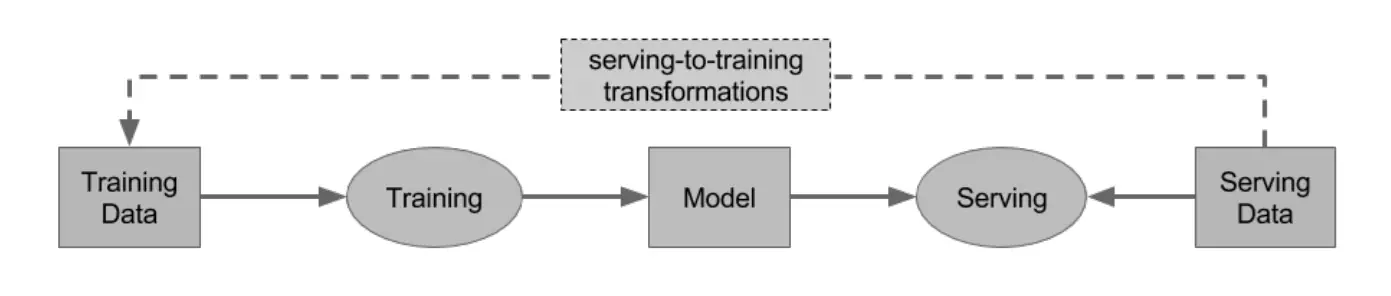 The pipelines for providing data in production and the data for model development are necessarily different, necessitating alignment. Image source: Polyzotis (2017)
The pipelines for providing data in production and the data for model development are necessarily different, necessitating alignment. Image source: Polyzotis (2017)
The Training Data \(\rightarrow\) Training \(\rightarrow\) model pipeline is what is built in step 4. The Serving Data \(\rightarrow\) Serving \(\leftarrow\) Model pipeline is what is built in step 3. The dotted line is the separate pipeline that needs to be aligned. These pipelines are necessarily under different constraints and environment, yet must produce equivalent data. In general, there is no perfect test to assert their equivalence.
Another source of misalignment is the model’s serialization and deserialization. Serialization is the process of saving a trained model in a format such that it can be loaded across multiple computers, programming languages or frameworks. The alignment across programming language is especially difficult, since it involve identically recreating the model’s logic using different representations of numbers, data structure and optimization routines, among other things. Today, there are well tested solutions, like TorchServing for PyTorch models and ONNX, which provides an open standard for representing deep learning and traditional machine learning models.
However, these are not airtight fixes to the serialization problem. The reason is there is no complete consensus abstraction of what defines a model. It cannot be everything that impacts the model’s predictions, since that would include the entire upstream pipeline, which is too large and distributed to represent with one tool. Inevitably, these serialization methods create gaps; differences in the models’ environments, not captured in serialization, are potential causes for model differences.
In reaction, contributors can apply the ‘Multi-Languages Smell’, as mentioned in Schelter (2018) and Sculley et al. (2015). This is to distrust any system that straddles multiple languages, and to insist on avoiding them without strong guarantees.
Misalignment of joined features and features over time
Enrichment is the process of improving a model with the addition of input features, often joined from a new data source. The new features are added in production if shown to be incremental in development. However, this offline process brings no guarantees of future feature homogeneity that the model may assume. The new feature set may have different latency, timestamp conventions, backfill triggers or null handling, all creating opportunities for future breakages.
Misalignment across time is another challenge. A feature with the same name can evolve in subtle ways as data engineering processes are updated or business requirements shift. For example, what starts as a simple user count might later be filtered to the reflect the company’s higher standard of an ‘activated’ user. A change like this may be done without relabeling, with only a partial backfill, and communicated with a company wide email. With different consequences, a data scientist might do nothing, shorten their backtest window, invert the feature change or drop the feature.
One solution is the use of pipeline metadata, which can be compared and asserted across features and time. However, as discussed in Schelter (2018), this metadata abstraction is often not sufficient for representing the model’s requirements and introduces new metadata management complexities.
Another solution is data quality checks, which verify that the data meets standards of completeness, consistency and accuracy. This is a useful line of defense, but as described in Polyzotis (2017), a model’s requirement for a feature cannot be discrete checked, since it is statistical and approximate. There is no perfect rule to detect feature drift, like there is to check whether a value is NULL or of a required data type. Further, as described in Rukat (2020), data quality checks normally must be specified by the modeler, since they depend on the downstream model. The necessary cross team communication makes their specification slow and unreliable.
Poor representations from new categories
A demand for a new product category paired with a short timeline creates pressure to reuse existing pipelines as much as possible. However, those pipelines were developed in little anticipation of the new category and can not provide the appropriate representation. For example, as mentioned in Stone 2013, this was a constant challenge for Amazon engineers, as they expanded their retail business into new product categories, from books to virtually everything. A symptom of this is the employees being forced to enter into the system whether a toy was hardcover or paperback.
In our experience, Lyft experienced this with different ride modes. What’s the singular price of a shared ride involving two passengers? What about three? In the shared category, many routines involving estimating elasticities, determining profitability and attributing financial line-items were not appropriate to apply, but applied nonetheless. When the shared rides were properly represented, there was additional complexity in the new pipelines to management.
The incomparability across products necessitates either two partially or entirely separated DELL routines. Considering humans are in the loop, this splits attention and slows cycles.
Challenge: Arduous, Vague, Delayed, Incomplete, Incorrect or Unavailable Feedback
Delayed rewards are an unsolved inhibitor to bandit algorithms. If action feedback is not observed for a long time, the algorithm can only slowly improve itself, degrading performance in the short run. In our analogy of bandit algorithms to multi-team Algo Ops systems, the sources of feedback degradation grows. Delays are only one source. More generally, anything that obfuscates the attribution of outcomes to actions degrades feedback.
To see this in the general context, we provide the following steps for applying feedback:
- An error or performance gap is identified: Feedback cannot begin without recognizing some deviation from expectations.
- The impact is estimated: This is to inform prioritization and the extent of the correction, since trade-offs are inevitable.
- The cause is located: The error or performance gap must be traced back to its cause.
- The solution is determined and executed: Knowing the cause is not necessarily knowing the fix. Using the estimate of impact, a fix is traded-off against alternatives, determined and executed.
For bandit algorithms, many of these are trivial since its theoretical problem statement declares that actions are the only thing to adjust and we are assured of their attribution to rewards. In an Algo Ops system, each is a source of failure in the feedback loop. Next, we explain common cases.
Observability does not represent model context and behavior
Observability involves building dashboards to reflect the models’ inputs, internals and outputs. The challenge is the dashboard must be interpretable to people while representing the high dimensional condition of the model. If one looks at the individual vectors fed to the model and its output, they can only inspect a tiny portion of the model’s traffic. Therefore, inputs are often averaged, as are the outputs. However, in some cases, the average input may be meaningless. The average location may be the middle of nowhere, and there is no average product category. Creating categorical dashboard filters is a common solution but divides attention. Ultimately, this mismatch hinders feedback steps 1-4.
Further, important behavior may be in the extremes and hard to detect in the aggregate. At Lyft, we discovered rare but impactful ‘bad experiences’, where prices or ETAs were extremely high, causing a rider to abandon the app permanently. The solution was to monitor these tail events directly and tune hardcoded rules to prevent them. This handled it, but it addressed a singular problem, required additional dashboarding and divided attention.
In short, passing system feedback through contributors’ minds creates friction and fog, complicating steps 1-4 and slows the Learn operation.
Regardless, observability is always necessary. No existing algorithm is sufficiently general to provide the types of corrections human attention produces.
Delayed Feedback
Much of what a business cares about is only realized over long time horizons. Quarterly profits are an obvious example. However, quarterly profits are a terrible objective for a bandit algorithm, since there’s no reliable method attributing the rarely observed fluctuations in quarterly profits to the myriad decisions it is intended to make. In our analogy to Algo Ops, this problem remains.
To illustrate, consider the goal of a long term forecasting systems. At Lyft, this was a primary focus of ours (Rich (2022)). Such a causally-valid system was used for planning; take the actions today which produce the most attractive future. However, delayed feedback is ambiguous feedback. If profitability forecasts are off, we could inspect errors in all observed intermediate variables (e.g. were we mistaken on rides?), but this does not necessarily inform the fix. The intermediate variable with the largest error may not in fact drive the profitability error. It may be due to a small upstream error to which profitability is very sensitive, and the model was mistaken on the level of sensitivity. Ultimately, domain intuition was relied upon, but this pervasive ambiguity makes this routine precarious for an aspiring Algo Ops system.
Uninformative Error Messaging
Continuing with Lyft references, suppose a contributor recognizes that conversion rates, the probability a ride is accepted after the price is seen, are falling below expectations after a price increase. We assume they can trace the cause to an exogenous variable, like a prediction of competitor pricing, failing a data quality check. The check alerts that the price is far above what can be reasonable expected, and so the model’s price sensitivity was incorrect.
The challenge is that an alert of ‘competitor price is too high’ does not inform on how to correct it. Inevitably, feedback is slowed, as teams communicate, fixes are proposed and iterations follow.
Lack of Model Reproducibility
The standard debugging procedure involves recreating the observe problem in an environment in which changes can be tested as solutions. However, in real time systems, the exact conditions that caused a model to behave problematically may not be recoverable. Among other things, this may be due to data collection timing, missing logging or a misaligned development environment. Ultimately, it prevents issues from being understood and corrected, interfering with the Learn operation.
Challenge: Gaps in Skills and Education
We argue that Algo Ops requires DELL components to be built well and executed in tight coordination. The knowledge to do so is not easily compartmentalized, but contributors must specialize to some extent, creating knowledge gaps. Ideally, everyone is aligned and knowledgeable of the motivations behind the full system’s design, but this is rarely so. We discuss a variety of consequences and causes.
First, it inhibits the four feedback steps described previously. A data scientist unfamiliar with the business’s ETL pipelines may be unable to trace the cause of a model’s performance degradation back to its source. A data engineer may be unequipped to set the right statistical data quality checks required by a downstream model. A contributor without causal inference training may misattribute outcomes to actions, resulting in ineffectual model updates. These are just a few example.
Second, the DELL operations cannot be well developed individually. In an effort of exploration, a data scientist underskilled in statistics may design an experiment insufficient for resolving the intended relationship. A data engineer unfamiliar with the model may writing logging that misses essential model behavior. A machine learning engineer underskilled in machine learning may create a deployment process which changes the model’s logic. Again, these are just examples.
Mailach (2023) describes a common cause as ‘Headless-Chicken-Hiring,’ where challenging projects are addressed with hiring, often of those with mismatched skills. This often delays the timeline and complicates the project, as more training, communication and coordination are required. They report common causes are unclear titles and uneducated hiring. Those making the hiring decisions do not understand what is required specifically by the task. As a consequence, they defer to unspecified terms like ‘data’ to match hires to projects. In reality, such terms are poor matching criteria. Mailach (2023) also cites skill shortages in the labor market as another commonly reported cause.
Challenge: Missing Culture
Especially among leadership, a culture of skepticism, scientific discipline, objectivity through data and algorithm supremacy is required for effective Algo Ops. Individuals should distrust intuitions, especially their own. People should look to experiments, whenever possible, to make decisions. They should read data to falsify rather than to confirm. They should notice and discourage speculation. They should insist on measurement. They should believe that, with sufficient data and at scale, mathematics and technology provide more effective decisioning than any group of people.
This culture may not exist because some do not have a scientific background, have been successful with their intuitions, are comfortable with manual operations, disapprove of the cost of scientific approaches, are impatient with the pace of knowledge discovery or find the mathematics opaque and irrelevant.
The consequence is that iterative improvement of an Algo Ops system cannot happen. For one to function at scale, it demands relentless effort in the form of applying a high experimentation standard to many well informed proposed changes. This can only be justified by those who believe it is the only approach.
Recommendations
In this section, we’ll provide recommendations to address the problems mentioned above. We break them down into recommendations on technology and development strategy.
Recommendations: Technology
To address these issues, companies have built a variety of technology solutions. Below, we discuss those that are common and effective.
Feature Stores
A feature store is a service designed to align features, in addition to efficiently managing their storage and compute. Lyft has the ML Feature Service for aligning features between development and production environments and between batch and event stream processing. Instacart developed their feature store for aligning development and production features, after experiencing the challenges described above. Uber has their Michaelangelo platform, which began with a feature store, first presented in Li (2017) on the merits of its alignment of batch and real time processing. Airbnb has Chronon to address the same problem and so does DoorDash. Lastly, Mailach (2023) identified the feature store as a common and useful solution when surveying MLOps engineers. These are well utilized technologies and necessary to avoid the often debilitating difficulties of misalignment.
Another benefit of a feature store is it centralizes data creation to a single team and interface. Data engineers can focus on testing, data quality checks, maintenance, and documentation, and data scientist can source from the feature store knowing it is consistently available across environments. This also mitigates an unmanageable proliferation of unsynchronized data pipeline.
A feature store is a targeted investment into feature misalignment, but not a root-cause fix. Many of the same alignments issues persistent, but are confined to a dedicated team and product. Additionally, there are new issues to consider. First, the centralized feature store prevents data scientists from self serving unsupported data. Second, individual features may feed into multiple models each with different data quality criteria, making any single criteria insufficient for some models.
Visualization Tools
Rich visualizations tools for viewing high dimensional objects are effective for feedback. Uber created Kepler.gl (picture below) for visualizing complex geospatial activity and Manifold for visualizing model behavior and performance. Instacart uses datashader to visualize their logistical operations. Doordash uses Grafana for real time model monitoring. Lastly, there are popular tools for visualizing the internals of deep learning models, like Netron, Weights and Biases and TensorBoard.
 Kepler.gl, created by Uber and now opensource, provides rich visualizations of region activity. Image source: Kepler.gl
Kepler.gl, created by Uber and now opensource, provides rich visualizations of region activity. Image source: Kepler.gl
These visualization tools help contributors understand models’ conditions and provide accurate feedback. Further, they often provide UIs, avoiding the need to arduously trace through code and data. This eases DELL cycles, producing more of them.
Machine Learning Platforms
A machine learning platform (‘ML platform’) is a broad term to describe a product designed to support the lifecycle of machine learning models. An ML platform may offer a model development environment, a feature store, distributed training, a model registry, model serving, cloud storage and user friendly interfaces. They centralize much of the redundant work for moving an ML model from development to production.
Due to the proliferation of ML model at some companies, ML platforms are normally well resourced and utilized. Uber’s ML Platform is Michelangelo. Lyft’s platform is LyftLearn. Airbnb has Bighead. Instacart has Griffin. DoorDash has Machine Learning Workbench. Each has developed their own to focus resources on the precarious process of moving a data scientists’ development model into a real time, large scale, product-integrated environment, and maintain it from there on.
Experimentation Platforms
An experimentation platform is designed to simplify, standardize, make reliable, and speedup experimental setup, deployment and analysis. It is a centralized product to allow contributors to focus only on the change to the website or app, the design of the experiment and interpreting results. Everything else necessary for launching the experiment is the responsibility of the platform.
An experimentation platform is a clear example of a partial Algo Ops system, since its functions neatly maps to the components:
- Run an A/B test \(\rightarrow\) Explore
- Record context and A/B outcomes \(\rightarrow\) Log
- Analyze results and decide A or B \(\rightarrow\) Learn
- Launch A or B \(\rightarrow\) Deploy
The value of such a system was expressed by Jeff Bezos when describing one of the earliest experimentation platforms, Weblabs:
 Jeff Bezos on the value of experimentation.
Jeff Bezos on the value of experimentation.
Many other companies have developed their own experimentation platforms. Uber developed Morpheus nearly a decade ago, and has since replace it with a more expansive system. Doordash has Curie. Airbnb an experimentation framework. Instacart has an adaptive experiment platform, Axon, which does much of the same control-treatment management, but is ‘adaptive’ in that it decides the relative value of the variants and allocates traffic accordingly. Lyft has one as well, described here.
Recommendations: Development Strategy
In this section, we use the above framework to make recommendations on what to build and how to build it.
What to Build
This section is to provide guidelines for deciding when its worth developing or improving a given Algo Ops system.
In order to create substantial decision feedback, look for decisions that produce a large amount of relevant and nearly independent data. That is, the decision should happen many times. Variables that discriminate a good from a bad decision should be observable, as should the decision variable itself and an immediately attributable reward. Decisions should not heavily influence each other.
By this description, setting prices on highly transacted goods is a decision worth targeting. In the case of rideshare, most factors that influence a rider’s decision to pay are observable: the starting and ending locations, the time, the weather, the supply of drivers, traffic conditions and the estimated time of arrival. The price itself and whether the ride was accepted are also available. Finally, rider acceptances are nearly independent; we can assume one riders acceptance is not influenced by another’s5. Decision problems of a similar character, especially those so immediately related to revenue, are good targets.
If it has not already been modeled thoroughly, start with the company’s transaction data. Transaction data, by requirements of financial reporting, is often of high quality. Second, transaction data informs purchase behavior, which is often an attractive target to influence. As an example, one of Amazon’s early technology successes was an unusual use of their transaction data, eventually labeled “Similarities.” It learned purchase correlations via customer baskets, which then informed item recommendations. In an interview, Eric Benson, an early Amazon engineer, attributes its success over competing technologies to the transaction data’s size and quality. More details can be found in Smith (2017).
Look for independence. Dependency and complexity are a scourge to Algo Ops. There are several forms of independence. Look for independence across system components; the deployment procedure should be independent of the specific model deployed. Look for independence across time; a short term signal, like a user reaction, is much better than slow moving time series, like user retention curves. Look for independence concurrently across variables; variables that can safely be assumed to be causally ‘upstream’ of other variables are good targets, especially when starting. Look for independence across systems; ridesharing companies simplify their operations greatly when they can treat their supply and demand populations separately.
Target breaks or frictions in DELL cycles. In a review of 14 Amazon employee interviews, we found five recommendations of fast, continuous feedback cycles. Feedback is slowed when its meditated through conversation, involves tracing complex and multi-language code and produces ambiguity. Several of our technology recommendations involve focusing resources to improve observability and lessen complexity, reducing the work to generate informative feedback.
Unless it is from a group dedicated to data quality and integrity, be skeptical of data sourced across organizations. To be incremental to a model, data pipelines must be align on difficult-to-check characteristics. Also, data is surprisingly problematic to communication across teams and organizations. As an example, Granlund (2021) studied the development of Oravizio, a software product that provides patient-level risk assessments for hip and knee surgery. This involved moving data between the hospital and those maintaining the model. They concluded that operations related to data communication were the greatest challenges.
Design for Control: The mechanism people use to control the Algo Ops system present an important design question. As discussed, quickly and reliable deploying well informed code changes is one ingredient, but it neglects the full scope of the design question. For instance, which variables should a person specify to guide an algorithm? In algorithmic trading, these are often risk tolerance parameters, like ‘value-at-risk’ or ‘risk tolerance’, establishing how much risk should be traded for expected return. In ridesharing, we considered parameters that traded short term profit for long term growth. More generally, it’s worth investing time to design control variables that are intuitive to humans to specify and fully corral the algorithm’s behavior.
Another question of control design is how to evaluate whether to shut the system down or fallback to a previous version. This may be specified via guardrail metrics, whereby crossing of a threshold value provided reason to investigate. Since a single metric is rarely enough to make the decision, a variety of metrics are often available. However, this creates an opportunity for confusion; what if some thresholds are crossed and others are not? A prioritization of metrics is a partial solution, but also introduces some complexity (e.g. how do you decide the prioritization?). In general, there is no perfect solution to this problem. We can only recommend careful and deliberate design, specific to the problem.
Build Strategy
Gall’s Law: A complex system that is working started as a simple system that was working.
From our experience and survey, we believe this is true and relevant. In anticipation of the aforementioned difficulties, it is wise to limits sources of complexity. Specifically, for developing Algo Ops, it may help to:
- Before anything else, gather an initial dataset: Simply getting the data may resolve questions. It may reveal that the data is not of the necessary scale, granularity, timeliness or structure.
- Define a small set of readily available success metrics: For feedback cycles to begin early, they must be with respect to objective measures.
- Start with a small geographic region: In the early days of ridesharing, models were built per region because regions were so incomparable. When starting, it is worthwhile place to start.
- Start with a small set of variables: A small set of variables is easier to model. Prefer to model those that are better understood.
- Start with a single, reliable data source: As mentioned, melding data sources is problematic and likely unnecessary when starting.
- Start with a small, skilled team: An Algo Ops system must be built in tight alignment with itself, so the contributors themselves must agree on the principles and communicate the details of their actions. This cannot be done across a large team and is challenging with unskilled contributors.
- Start with building the baseline model: A baseline model establishes something objective to measure improvements from. Without it, there is no frame of reference to declare where the model is good or not.
- Use only one programming language: Multiple languages is often unnecessary, and sometimes motivated by the preferences of team member. It can present serious technical difficulties and should be avoided where possible.
- Establish explicit DELL components: This was the strategy in Microsoft’s bandit technology. To reiterate, these component operations are necessary for any Algo Ops decision system, so labeling them may give them the proper priority and attention.
- Execute the first feedback system early: Improvements come from DELL cycles. Getting to them quickly is to improve the system more quickly.
It should be cautioned that most simple systems are not on the path to an effective complex one. In other words, the initial system must be carefully designed. Below are some things that must be anticipated up front.
- Interfaces: As best they can, abstractions should anticipate future functionality. If it does not, updating abstractions can be an error prone and laborious process. To do this, contributors should speculate on the future system and its requirements.
- Scaling: If the system is expected to scale, scaling should be anticipated from the start. Prototyping without anticipating scaling may just produce an irrelevant prototype.
Lastly, restarting may be a reasonable option. For reasons of incomplete abstractions, Uber rebuilt their experimentation platform. Amazon in 2016 had to redesign much of their supply chain systems. The reality is even thoughtful and well educated engineering design is not enough to protect against rewrite-worthy complexities in the future.
Conclusion
This article has emphasized that algorithmic operations cannot operate effectively without the components Deploy, Explore, Log and Learn. Each must be done well and in tight coordinating. This is made challenging by separated software, data, teams and the required coordination efforts to compensate. We have provided tried and true technologies and recommendations to ease the path to Algo Ops.
We would like to thank a few of our peers for their helpful comments on this article: Alex Chin, Sumeet Kumar, Wilhelm Leinemann, Sameer Manek and Varun Pattabhiraman.
References
-
A. Agarwal, S. Bird, M. Cozowicz, L. Hoang, J. Langford, S. Lee, J. Li, D. Melamed, G. Oshri, O. Ribas, S. Sen, and A. Slivkins. Making Contextual Decisions with Low Technical Debt. ArXiv. 2017
-
D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M.l Young, J. Crespo, and D. Dennison. Hidden Technical Debt in Machine Learning Systems. NIPS. 2015
-
E. Zangerle and C. Bauer. Evaluating Recommender Systems: Survey and Framework. ACM Computing Surveys, Volume 55, Issue 8. 2022.
-
N. Polyzotis, S. Roy, S. Whang and M. Zinkevich. Data Management Challenges in Production Machine Learning. SIGMOD. 2017
-
A. Mailach and N. Siegmund. Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront. IEEE Xplore. 2023
-
E. Li, E. Chen, J. Hermann, P. Zhang and L. Wang Scaling Machine Learning as a Service. International Conference on Predictive Applications and APIs. 2017.
-
T. Granlund, A.Kopponen, V. Stirbu, L.Myllyaho and T. Mikkonen. MLOps Challenges in Multi-Organization Setup: Experiences from Two Real-World Cases. ArXiv. 2021
Footnotes
-
I should be careful to not given Amazon too much credit. Many companies pre-dating Amazon contributed to development of algorithmic operations. For example, American Airlines introduced dynamic pricing in the 1980’s and Barilla introduced the Just-in-Time Distribution style of inventory management. ↩
-
A model, in this context, is essentially a function that is learned from data. That is, it produces an output from an input, where the input-output mapping is informed by historical data. ↩
-
We should differentiate between two types of modeling: predictive modeling and causal modeling. Predictive modeling seeks only to predict outcomes from observations. A predictive model may be thought of as a noninteracting observer, inferring unseen variables from seen ones. Causal modeling is a strictly larger task, subsuming predictive modeling. A causal model is there to predict and optimize the actions of something operating within an environment. It must disentangle actions, their effects and the environment in order to estimate counterfactuals and pursue the most attractive one.
The distinction relevant for our discussion is that causal modeling requires exploration. Exploratory or experimental actions are strict requirements for any system with a meaningful impact on its environment.
Since it is typical for actions to impact the environment, we will assume causal modeling is the goal from here on. For more information on the distinction between predictive (or ‘associative’) and causal modeling, see this note on Judea Pearl’s Causal Hierarchy. ↩
-
However, it is not a well contained black box; the specific modeling task has strong implications throughout the system. The granularity, size, latency and frequency of the data all follow considerations of the modeling problem. The design and extent of experimentation, observability and evaluation similarly follow. As an example, much of Lyft’s early scientific investment was to A/B test market level changes. Further, the modeling problem will have implications for the model’s complexity, which will have implications for model development and deployment. ↩
-
The reality is more complicated, since prices influence future driver supply, which correlates future acceptance, but our assumptions works at a first approximation. ↩