MLflow
Posted: Updated:
In this article, we’ll review MLflow, an open source tool for easing the management of machine learning models. At the end, we’ll provide a one page PDF summarizing our take.
MLflow Tracking
MLflow addresses a common circumstance of data scientists. They are experimenting with a model (e.g. adjusting its hyperparameters, changing the preprocessing, updating the data) to get good performance. The annoyance is that these experiments are distributed across space (e.g. using multiple notebooks) and time (e.g. changing hyperparameters within the same notebook), and that makes finding the best model difficult. A disciplined scientist will collect all experiments into one place for comparability, but this is an additional, manual and unreliable workflow.
MLflow’s solution is to provide a UI which displays these experiments. To do this, a user needs only to update their model training code with a few API calls. Specifically, a user wraps their model training code within mlfow.start_run() and .log_params-the values they wish to compare across experiments:
mlflow.set_experiment("experiment_1")
with mlflow.start_run():
mlf.log_param("lr", 0.001)
# Model training code goes here
mlf.log_param("loss", loss)
Every time this code block executes, the parameter lr and the resulting performance loss are logged and made available via an UI, accessible with the following CLI command:
mlflow ui --port 5000
Giving something like:
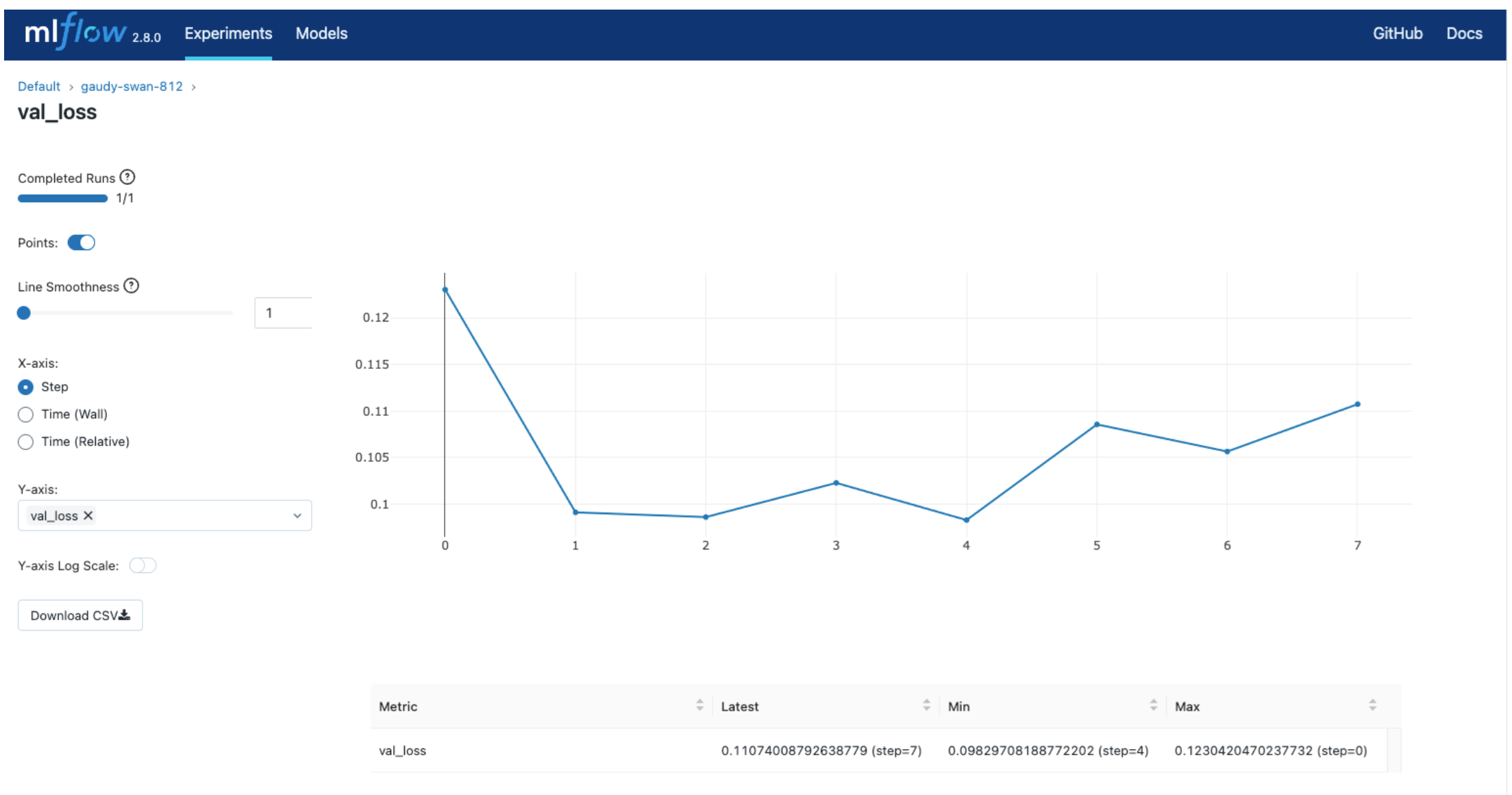
Alternatively, remote experimental tracking is available, so multiple people develop on the same model.
What we’ve done is provide a very brief description of MLflow Tracking. The other core components that caught our attention were MLflow Models, MLflow Projects and the MLflow Registry.
MLflow Models
For portability (something essential for production ML), MLflow provides model standardization. They provide methods which convert a variety of models (e.g. sklearn, pytorch, etc.) into their standard format1, which can then be loaded and/or served in different environments, such as Docker, Apache Spark, AWS SageMaker, and Azure ML.
To support this, MLflow offers ‘flavors’, model abstractions that permit execution in different environments. Some example flavors are python_function, sklearn, pytorch, and onnx. These allow models to be saved/loaded in a variety of environments, provide interoperability between ML libraries, support multiple inference methods, and help track dependencies and metadata.
MLflow Projects
To a data scientist, a directory might be their final deliverable. All one needs to do is enter the directory and run a CLI command. For example, that command might pull in the data, train the model, make predictions and store those predictions in a shared database.
For collaboration and reproducibility, MLflow Projects standardizes this practice. That is, it provides a way to package machine learning code so that it can be shared and executed reproducibly and across environments. Essentially, an MLflow Project is a directory containing code structured according to certain conventions. To do this, a central element of MLflow Projects is the MLproject file, a YAML configuration that defines the project’s entry points (its run commands), dependencies, and execution environment.
Further, MLflow Projects permit multi-step workflows, where different tasks (e.g. data processing, model training, and evaluation) can be orchestrated in a structured pipeline. These workflows can be executed sequentially or in parallel.
MLflow Registry
The MLflow Registry is a centralized model store. It allows teams to track model versions, add descriptions, and assign metadata to models. It’s especially good for collaboration, as individuals can track and contribute to the same ‘champion’ model.
Strengths
From our experience and surveying Github issues, reddit threads and other user experience sources, we determine its primary strength:
-
Open source and Active: As industry applications have grown, the developer community has only accelerated. Major companies use MLflow, which speaks to its enterprise viability. The documentation is detailed. Github issues are discussed promptly, normally with a solution planned or highlighted. Newer applications, like LLM specific utilities, are feature incomplete but are receiving active attention.
-
Flexible: A challenge of machine learning model management is supporting the wide and diverse software ecosystem for ML modeling. MLflow has made impressive progress on this task, supporting a complex variety of models. Github issues suggest LLM support is incomplete, but this is receiving active attention (e.g. they recently announced an integration with LLamaIndex).
-
Minimalistic: MLflow understands that frequent calls to their API is a bad thing. Since many workflows are common (e.g. training a scikit-learn model), their methods offer sensible defaults, requiring less user specification, and they offer the
auto_logmethod, which allows users to avoid making logging calls. -
Intuitive: Their UI for tracking and viewing experiments is intuitive. In our opinion, they provide plots of the most typical views of experimental results. That said, users have complained about UI inflexibility. Certain specialized views are not available and require users to code their own visualizations.
Weaknesses
Also from our experience and surveying user experiences, we determine its primary weaknesses:
-
DevOp Requirements: MLflow is self-hosted; it is code that the user runs on their own systems. This is a virtue to some, but it creates an infrastructure management burden, which does not exist with fully managed alternatives, like Weights & Biases. For this reason, MLflow is more appropriate for companies staffed with this expertise.
-
Lock-in: MLflow offers a managed alternative, Managed MLflow by Databricks. This essentially outsources the infrastructure work to Databricks, which has added benefits (e.g. it can serve a user’s model via an API), but also has downsides. The fixed cost of migration can be high and the variable costs of running jobs can be high. Further, it creates lock-in going forward; once integrated, future database migrations are notoriously challenging.
-
Scaling: For the largest applications, we’ve heard complaints of MLflow’s sluggishness and insufficient support for distributed training and scaled ETL jobs. Managing a massive amount of artifacts (data produced during training) or parameters can create slow API calls and a lagged UI. Further, MLflow was not originally developed for scaled applications. Dedicated alternatives, which offer MLflow-like tracking, are often preferred in such cases.
Summary
To make this discussion portable, we’ve packaged the main points into a downloadable PDF: