CoreWeave User Experience: A Field Report
Posted: Updated:
In the fast-evolving world of enterprise AI and machine learning, the demand for specialized cloud solutions is surging. Yet traditional hyper-scalers like AWS, Azure, and Google Cloud often fall short of meeting the needs of specialized AI/ML projects. If you’re an enterprise AI/ML leader, you’ve likely experienced moments when your current provider fails—whether due to lagging performance, rising costs, delayed access to the latest hardware, or a lack of tooling—prompting a search for alternatives. Vendor lock-in can make these challenges even harder. Once your workloads are tightly coupled with a provider’s ecosystem, switching becomes costly and operationally complex, reducing your ability to respond to innovation, improve efficiency, or leverage better infrastructure options elsewhere.
While there’s no shortage of detailed comparisons analyzing provider specs, strategies, and financials, the real challenge remains:
As an AI/ML practitioner, how do you actually decide on the right GPU cloud provider?
We explore the key decision triggers and offer a practical framework to help you make this decision. From our experience and surveying the space, it’s clear that in some cases, a different vendor is the better choice. We’ll kick off with an in-depth look at CoreWeave—a GPU cloud provider known for raw compute, now expanding into developer experience and higher-level tooling. This analysis reflects the current experience and assessments from an enterprise AI/ML team as of March 2025.
What Makes CoreWeave Stand Out
CoreWeave’s pricing structure is one of its most compelling advantages—particularly when compared to traditional hyper-scalers like AWS. Like many emerging GPU cloud providers, CoreWeave operates in a more dynamic, marketplace-style pricing environment that allows for greater flexibility and negotiation.
This often results in 30–50% lower costs for GPU-heavy workloads.
We go into more detail in the pricing section below, but the takeaway is simple: if you’re training models at scale or running high-throughput inference, providers like CoreWeave can offer meaningful savings over hyperscaler alternatives.
Another key advantage is its immediate access to the latest NVIDIA GPUs—such as the GB200 and H100—typically within weeks of release, a speed that often outpaces competitors. One reason technical leaders pick hyper-scalers is because they assume they have the best capacity. But since hyper-scalers are so well subscribed, this doesn’t mean they offer the best GPU availability. CoreWeave, however, has plenty of scale—32 data centers with over 250,000 GPUs—offering ample room for even massive foundational model training, a critical need for AI/ML leaders facing compute-intensive initiatives.
Performance is another strong point. Unlike hyper-scalers’ virtualized environments, where multiple tenants share resources, CoreWeave uses bare metal servers. This means your code runs directly on dedicated hardware, eliminating virtualization overhead and delivering faster, more predictable performance for GPU-heavy tasks like model training or simulations. Additionally, CoreWeave provides essential managed services—like the CoreWeave Kubernetes Service (CKS) for orchestration and Weights & Biases for experiment tracking—that streamline workflows and support the priorities of AI/ML teams.
What to Watch For
Despite its strengths, CoreWeave doesn’t offer the full-service ecosystem you’d find with hyper-scalers like AWS, Azure, or Google Cloud.
If your project depends on managed databases, integrated analytics, or prebuilt AI platforms like SageMaker or Vertex AI, you’ll need to piece together those components using third-party tools or manage them yourself.
The onboarding process also creates friction. Rather than a self-service sign-up, you need to schedule a meeting to get started—adding potential delays for teams hoping to spin up infrastructure quickly. And while CoreWeave provides strong building blocks for cloud infrastructure, using them effectively often requires significant technical expertise. Running Kubernetes clusters, managing Slurm-based batch jobs, and optimizing resource allocation all demand familiarity with cloud-native and HPC-style workflows.
Additionally, the absence of prebuilt inference APIs means teams must develop custom solutions or rely on third-party tools that offer pre-deployed inference APIs for popular models, introducing complexity that may hinder smaller teams or those seeking straightforward, streamlined workflows.
Who Should Use CoreWeave?
CoreWeave is ideal for technically proficient teams of ML scientists and DevOps engineers who can effectively utilize its bare metal infrastructure and flexible tools for custom, high-performance workflows. Teams with strong skills in container orchestration (e.g., Kubernetes), workload scheduling (e.g., Slurm), and cluster management will thrive. Its raw computational power is particularly suited for training large models or running complex simulations where control and optimization are prioritized over ease of use. Large-scale projects requiring long-term GPU access will benefit from CoreWeave’s efficiency and volume discounts, especially through multi-year leases. Enterprises or research groups committed to sustained AI/HPC workloads can capitalize on its cost savings and access to advanced hardware.
Who Might Find CoreWeave Challenging to Use?
Teams without dedicated infrastructure expertise may find CoreWeave challenging to adopt. Unlike more turnkey platforms, it requires hands-on setup and ongoing management of orchestration and scheduling tools. Small teams, early-stage startups, or non-tech-centric enterprises experimenting with AI may struggle if they lack in-house resources to manage GPU infrastructure. Additionally, CoreWeave’s more rigid onboarding process and focus on compute over end-to-end developer experience means users must take on more operational responsibility. For those seeking a plug-and-play platform or a simplified interface, other providers may offer a more accessible alternative.
A Note on Pricing
CoreWeave’s pricing structure stands out as a compelling alternative to hyper-scalers like AWS, offering a blend of flexibility, negotiation room, transparency, and lower overall costs—particularly well-suited for AI/ML workloads.
Unlike hyper-scalers, which often break down charges into separate categories like compute, storage, and networking, CoreWeave bills with a per-instance, per-hour pricing model. Each instance bundles GPUs, CPUs, RAM, networking, local NVMe storage, and pre-configured software into a single rate, making costs easier to predict and manage.
With hyper-scalers, costs can unexpectedly spiral as you scale—between egress fees, premium storage tiers, and unexpected service charges, it becomes difficult to accurately model and forecast spend. For AI/ML teams, especially at startups or non-tech-centric firms, CoreWeave’s flat-rate, bundled approach is a strong differentiator.
As of early 2024, CoreWeave lists an 8x H100 GPU instance at $49.24/hour under its Classic Pricing model. This “sticker price” serves as a baseline in a highly dynamic market where the actual cost varies based on the pricing structure:
- Spot Pricing: The lowest-cost option, offering interruptible rates ideal for non-critical workloads like batch inference. With a one-minute eviction risk, it’s not suitable for training.
- Contract/Reserved Pricing: Offers guaranteed access with rates locked in from 1 month to 3 years. A middle-ground option balancing reliability and cost, though fewer teams are committing long-term due to rapid market changes.
- On-Demand Pricing: The most expensive but most flexible option. Ideal for development, testing, or burst workloads when instant access is more important than cost-efficiency.
Today’s GPU rental market is in a price war. H100 rates have dropped from $8/hour in 2023 to as low as $1/hour in 2025, according to Cybernews. While these figures don’t reflect CoreWeave-specific pricing, they highlight industry-wide pricing pressure—and why negotiation is critical.
Your key advantage with CoreWeave—and other emerging GPU cloud providers—is the ability to negotiate. Unlike AWS, where discounts are tied to rigid upfront commitments and long-term reserved instances, CoreWeave offers more adaptable contracts and is often quicker to reflect market trends in its pricing. While exact discounts aren’t public, it’s widely recognized that committed customers can negotiate substantial reductions off list prices. A startup may get modest savings, while a large enterprise with multi-year usage can secure deeper cuts.
Estimates vary—some reports suggest CoreWeave can be 30–50% cheaper than hyper-scalers for GPU workloads, and anecdotal claims point to discounts of 50–70% off list rates. The reality likely depends on your specific use case, workload type, and negotiation leverage.
Ultimately, listed prices are just the starting point. Teams that track GPU market benchmarks (e.g. $1–3/hour for H100s) and negotiate flexible, short-term contracts are best positioned to capture cost advantages—especially in a fast-moving market where locking into a multi-year rate today could mean overpaying tomorrow.
Our Overview of CoreWeave Tooling
Below is our overview of CoreWeave’s tooling and platform architecture—broken down by segment to highlight what’s included, what stands out technically, and where teams might encounter friction. This breakdown is designed to help enterprise AI/ML teams assess CoreWeave’s strengths and potential challenges across the full stack.
| Segment | What They Offer | What They Do Well | Technical Origin | Challenges |
|---|---|---|---|---|
| Infrastructure | Access to GPUs (GB200, H100), 32 data centers, and bare metal servers for high performance. 250,000 GPUs online | Delivers great computational power and higher GPU cluster performance than alternative solutions. Model FLOPS Utilization (MFU) exceeding 50% on NVIDIA Hopper GPUs | Elite Cloud Services Provider (CSP) within the NVIDIA Partner Network (NPN), ensuring early access to hardware | Some users note occasional congestion during peak usage, though it’s rare |
| Networking / Interconnect | High-performance networking with InfiniBand, BlueField DPUs, and upgraded Ethernet, built for AI and HPC workloads | Enables fast, low-latency GPU-to-GPU communication with non-blocking interconnects—ideal for distributed training and inference | Built on NVIDIA Quantum-2 InfiniBand, Spectrum switches, and in-house infrastructure | N/A |
| Container Orchestration | CoreWeave Kubernetes Service (CKS), a managed Kubernetes platform optimized for GPU workloads, with out-of-the-box production readiness | Simplifies container orchestration with fast spin-up times and strong GPU performance, leveraging familiar Kubernetes tools. | Developed initially in-house with Loft Labs using vCluster, integrated directly with CoreWeave’s bare-metal infrastructure for efficiency. | May still limit user-facing “ease-of-use” compared to traditional cloud-native Kubernetes services |
| Workload Scheduling | SUNK for efficient scheduling, Helm chart with GitOps, ideal for HPC/AI training | Optimizes resource use, reduces idle compute, seamless batch job management | Developed with SchedMD, combines Slurm and Kubernetes, reflects HPC focus | Complexity for beginners, potential integration challenge |
| AI Development Tools | Weights & Biases integration for experiment tracking, model management, collaboration | Streamlines ML development, reduces trial-and-error, deep integration, excels in collaborative tracking and visualization | Brought through acquisition in March 2025 | N/A |
| Inference Services | Serverless inference with autoscaling, raw GPU support for custom setups, and Tensorizer for faster model loading | Fast scalable inference with cost-efficient bare-metal GPUs. | N/A | No prebuilt APIs, custom builds required, |
We also find the below graph from CoreWeave to be especially informative about how their product is layered.
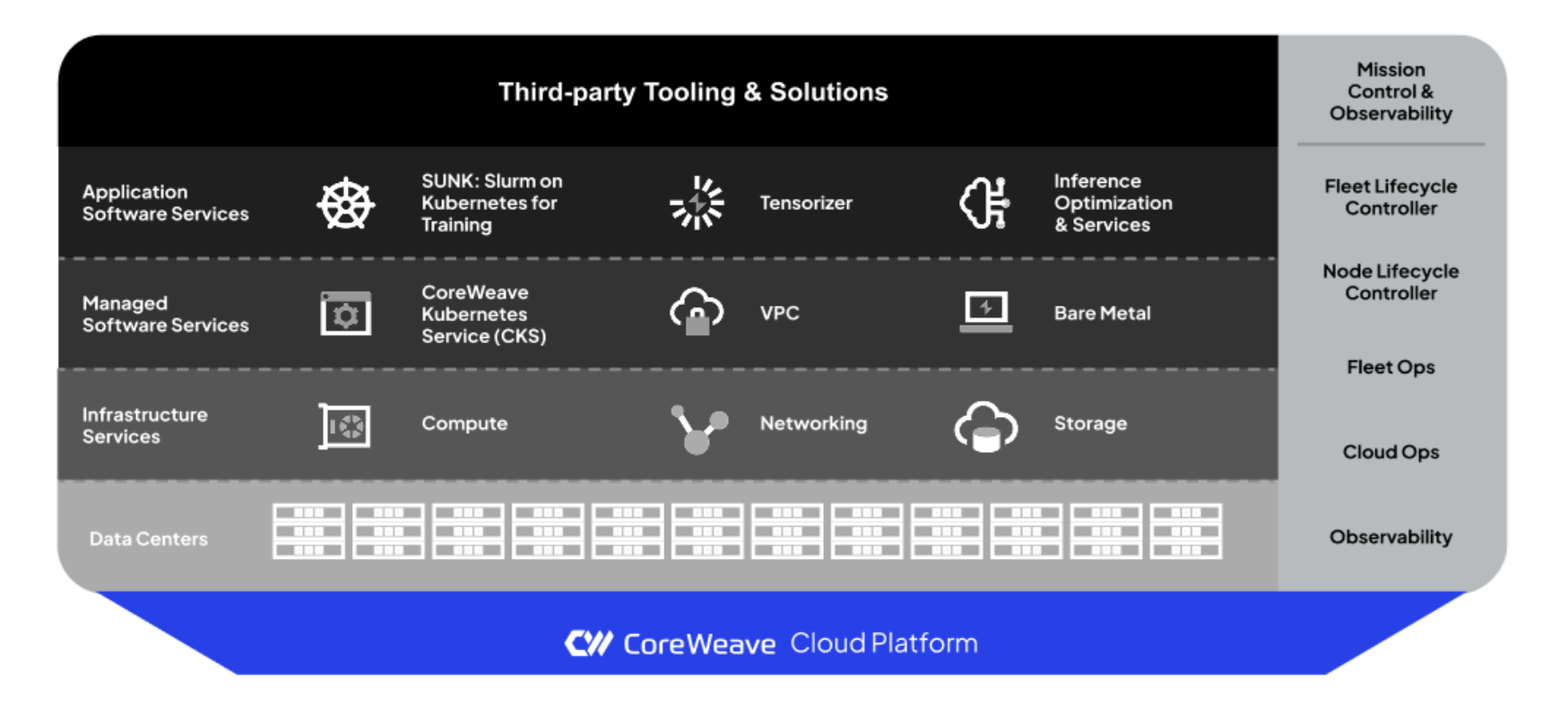 CoreWeave Layered Architecture Stack. Source.
CoreWeave Layered Architecture Stack. Source.