AI Inference Platforms: A Practical Guide
Posted: Updated:
In recent years, the focus of AI innovation has shifted from research-heavy model training to optimized inference, where the goal is to retrieve AI model responses quickly, cheaply, and in large volume. Optimizing these is essential for profitable AI products that attract users and scale, explaining the industry’s new emphasis.
In this article, we will unpack the AI inference landscape, emphasizing two types of critical service platforms beyond proprietary model providers: Managed AI Inference APIs and DIY (Do It Yourself) GPU Infrastructure. We will explore their cost, performance, and operational implications to inform how enterprises choose between them. To do this, we will provide an approximate framework for understanding this inference landscape and discuss how companies have progressed through it.
Why AI Inference Matters
Despite what news coverage may lead you to believe, the most common challenge of AI builders emerges post-training in deploying models to users. Inference describes the process where trained models produce predictions or responses, often in real-time. Increasingly, users expect AI products to be cheap, reliable, responsive, and high volume, which translates into extreme standards for the AI inference layer.
To be exact, the AI inference layer refers to the full stack of services, hardware, and software that sit between a trained model on disk and the end-user request for a prediction. More generally, it refers to all companies and products which participate in this layer.
The complexity of scaling AI inference stems from two intersecting forces. First, companies must weigh trade offs across the stack—balancing flexibility, control, and simplicity—just as they do when choosing between frontend frameworks or database systems. Different workloads and engineering needs demand different levels of abstraction. Second, organizations move through an AI maturity curve. Early-stage teams prioritize speed and ease of use, often relying on proprietary APIs. As they scale and cost pressures grow, they shift1 toward managed APIs for open-source models. Eventually, more advanced teams should transition to DIY GPU Infrastructure to maximize performance and control. These vertical and horizontal forces combine to shape how companies adopt and evolve their inference platforms.
Three Categories of Inference Services
We find the following chart to be a useful, approximate view of the AI inference landscape:
 Platform types and their broad features
Platform types and their broad features
Proprietary APIs: Powerful, Polished, and Pricey
Proprietary APIs from hyperscalers and foundation model creators—like OpenAI (ChatGPT), Anthropic (Claude), and Google DeepMind (Gemini)—offer direct access to their own frontier models through cloud-hosted endpoints. We see the following as their key advantages of the alternatives:
Key Benefits:
Model Quality: Access to the most advanced models on the market, often with early access to new releases.
Zero Infrastructure Lift: Fully hosted APIs abstract away all deployment, orchestration, and scaling concerns.
Enterprise-Grade Ecosystem: Deep integration with cloud platforms, plus support for security, compliance, and SLAs.
Developer Experience: Rich SDKs, detailed documentation, and support designed for fast integration.
Despite the ease of use, these platforms come with constraints. Pricing is significantly higher due to embedded IP costs. Model weights are inaccessible, fine-tuning is limited, and vendor lock-in can become a concern as usage grows and dependencies deepen.
Ideal Users: Proprietary APIs are ideal for well funded startups, innovation labs, or corporate teams launching early AI experiments. For example, if you’re building a beta version of a customer service chatbot and need best-in-class performance without hiring an ML team, OpenAI or Anthropic is the fastest path to market. Think: “one PM, one frontend dev, one API key”.
Managed AI Inference APIs: Efficient, Cost-Effective, and Flexible
Managed AI inference APIs, provided by platforms like Together.ai, Fireworks.ai, and Replicate, offer a balanced solution between ease of use and cost efficiency. These platforms host open-source and fine-tuned models—such as LLaMA, Mistral, and Mixtral—via performant, developer-friendly APIs.
Key Benefits:
Cost Efficiency: Lower prices per token by avoiding proprietary model licensing.
Flexibility: Support for model selection, parameter tuning, and user-provided fine-tunes.
Performance Optimization: Techniques like batching and speculative decoding improve latency and throughput.
Ease of Use: APIs simplify scaling and deployment without requiring users to manage infrastructure.
Together.ai and Fireworks.ai, for instance, prioritize rapid inference speeds, high uptime, and a broad catalog of supported models, catering to developers who value performance and variety. Others, like Replicate, focus on ease of use, while platforms such as Anyscale offer scalability for enterprise workloads
Ideal Users: Managed APIs are great for startups or scale-ups that have validated product-market fit and need to scale cost-effectively. For instance, if you’re running a SaaS platform with embedded AI features—like an edtech tool that summarizes reading material—and you’re hitting $50K/month in OpenAI bills, switching to Fireworks or Together with LLaMA models may cut your cost by 10x with minimal migration work.
DIY GPU Infrastructure: Maximum Control, Deep Cost Savings
DIY GPU Infrastructure providers—including RunPod, Lambda Labs, Vast.ai, and Modal—offer raw or semi-managed GPU access for teams that want complete control over model deployment. Users configure everything from runtime environments to model hosting using their preferred tools and frameworks.
Key Benefits:
Lowest Compute Costs: Access to bare-metal GPUs at rates well below hyperscaler pricing.
Full Customization: Control over every layer—from model weights to system architecture.
Scalability: Ideal for high-volume inference, fine-tuning, or complex deployment pipelines.
Vendor Flexibility: Many providers support spot instances, shared GPUs, and user-owned containers.
This category demands strong technical expertise. Users are responsible for uptime, orchestration, and operational tuning. While some providers ease setup with prebuilt containers or notebooks, success requires considerable ML engineering experience.
Ideal Users: DIY GPU Infrastructure is best for technical AI-native teams with strong infra capabilities and tight cost control needs. For example, if you’re operating a workflow automation agent, demand is growing fast, and you have ML engineers on staff, switching to RunPod or Lambda is probably the right choice. It could lower batch inference cost by ~80%, and it permits fine-tuning, for sharping your model to the specific task. For this category, think: “we built our own orchestration layer, and our infra team cares about cents per token.”
How to Choose Inference Platforms
Choosing an AI inference platform also depends strongly on where the company is in its AI product development. That is, it is a function of AI operational maturity, how far the product has moved from experimental to scaled deployment. This is a well traveled path, albeit at very different speeds. From this perspective, we see the AI inference categories as:
Proprietary APIs are great for fast prototyping. You get access to the best models with zero infrastructure lift.
Managed Inference APIs are the next step when costs start to rise. You keep the simplicity of APIs but gain more control and lower token costs by switching to open-source models.
DIY GPU Infrastructure is the final stop for experienced teams that need the lowest costs, the most control, and/or strict privacy guarantees.
Next, we will walk through how this might look like in practice.
AI-Native Startups: From Idea to Infrastructure in 12 Months
Startups typically begin with proprietary APIs like OpenAI or Anthropic. It’s the fastest way to launch—no infrastructure, no orchestration, just plug-and-play endpoints that let small teams ship fast. But growth brings pressure. Within months, many teams run into what we call inference shock—costs scale with usage, and $100K+ monthly API bills aren’t uncommon.
At that point, it’s wise to migrate to Managed Inference APIs like Together or Fireworks. These platforms offer up to 10x savings by serving open-source models with optimized infrastructure. Teams still use simple APIs, but gain more control over model choice, decoding parameters, and batching behavior.
Eventually, some teams outgrow even managed APIs. If you’re running a high-scale LLM product—or need fine-tuned privacy, latency, or cost control—your next move is DIY GPU Infrastructure. It’s the lowest-cost, highest-control option, but requires serious MLOps.
Enterprises: Same Path, Slower Pace
Traditional companies follow the same pattern—but over longer timelines.
They start with proprietary APIs to test ideas safely. These platforms require no infra lift and carry little legal or operational risk—perfect for proofs of concept like internal chatbots or summarization tools.
As pilots mature, cost and compliance come into play. Enterprises shift to Managed APIs that offer better economics and more flexibility, often in private cloud or VPC setups.
Finally, for production-critical workloads, especially in healthcare, finance, or regulated environments, some move to DIY GPU Infrastructure. Whether on-prem or in isolated cloud environments, this gives teams maximal control over cost, performance, and data residency.
A Modeling Exercise: What Does 20 Million Tokens Cost?
To ground this discussion, we modeled a representative workload: 20 million tokens of inference.
That’s equivalent to 10,000 user queries with 2,000-token responses each, enough to power a summarization tool or a RAG product. This scale is common for startups transitioning out of experimentation or for larger teams running realistic pre-production tests. The point of this benchmark isn’t to name the cheapest provider. Instead, it shows how cost depends on four core variables: platform type, model architecture, latency needs, and optimization strategy.
The table below offers a directional snapshot (as of May 2025) across several providers. These aren’t exact quotes, but they reflect real-world pricing ranges and architectural patterns.
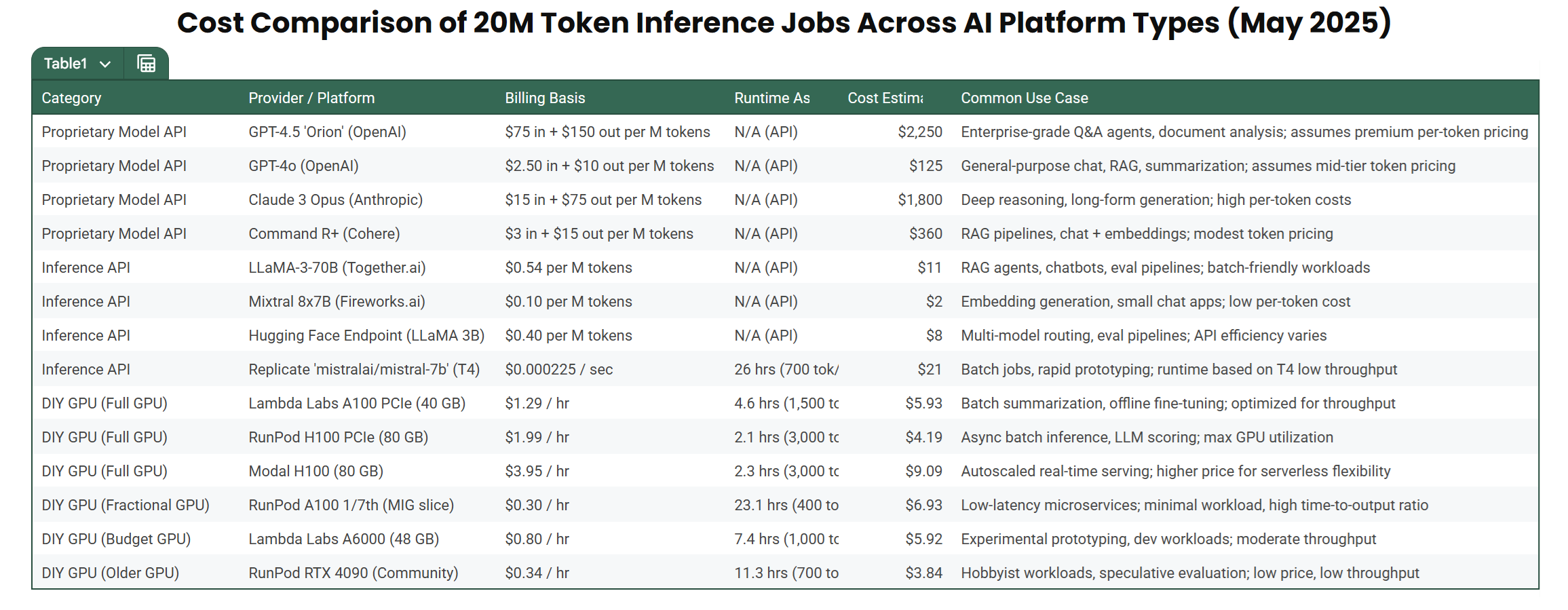 Cost Comparison of 20M Token Inference
Cost Comparison of 20M Token Inference
Why API Token Prices Vary
While API costs are simple to calculate, the actual price per token varies heavily depending on business model, infrastructure, and workload pattern:
Model Type & IP: Proprietary models like GPT-4.5 or Claude 3 Opus come with high IP markups to cover R&D costs. Open-source models like LLaMA 3 or Mixtral, by contrast, are far cheaper to serve.
Batching & Throughput: Providers optimize behind the scenes. For batch jobs (e.g., document summarization), token costs are low due to efficient GPU utilization. For real-time apps (e.g., chatbots), compute is underused between requests, raising costs per token.
Platform Overhead: Proprietary APIs bundle extras like SLAs, customer support, and compliance guarantees. These drive up margins. Managed APIs like Together or Fireworks keep overhead lower but may offer fewer enterprise-grade features.
Latency Sensitivity: Low-latency requirements (e.g., streaming output or tight response times) reduce batching opportunities and increase GPU hold time, leading to higher per-token costs.
Autoscaling & Monitoring: Some platforms include observability, routing, and autoscaling in the price; others charge for it separately or bake it into higher base rates.
In other words: the price is heavily shaped by technical, operational, and business factors behind the scenes.
The best approach is to measure it empirically. If it’s a batch job, 20M tokens might take just a few minutes. If it’s real-time at 60 tokens/sec, it’s a totally different story.
With that in mind, the runtime and cost estimates in the next section should be viewed as directional benchmarks, not absolute truths. They’re built on throughput and GPU utilization assumptions (e.g. 1–2M tokens/hour for large LLMs), and aim to help compare relative cost profiles across providers, not predict your exact bill.
In production? Always benchmark on your actual stack.
Cost Formulas for AI Inference
To give a sense of how these costs are determined in practice, we can break down the two main pricing approaches: DIY GPU rental and API token pricing.
DIY GPU Platform (hour-based)
The economics of DIY GPU Infrastructure is a straightforward function of resource time and efficiency:
\[\textrm{Cost} = \textrm{GPU Hourly Rate} \times \frac{\textrm{Total Tokens}}{\textrm{Throughput}\times\textrm{GPU Utilization} \times 3600}\]where:
- GPU Hourly Rate = hourly price of the rented GPU (e.g., $1.99/hr for RunPod H100)
- Throughput = average number of tokens processed per second (heavily model and batch size dependent).
- GPU Utilization = the fraction of time a GPU is actively executing instructions.
This simple formula highlights how optimization strategies like batching, speculative decoding, and quantization can directly reduce the cost of GPU-based inference.
Managed API Platform (token-based)
At first glance, API pricing appears more predictable:
\[\textrm{Cost} = \textrm{Total Tokens} \times \textrm{Price Per Token}\]However, in reality, Price Per Token is not a static number; it is composed of several moving parts. It can be thought of as:
\[\begin{align} \textrm{Price Per Token} &= \textrm{Base Cost} + \textrm{Infrastructure Cost} \\ &\phantom{=} + \textrm{IP Markup} + \textrm{Batch/Latency Penalty} \end{align}\]where:
-
Base Model Cost reflects the compute cost for serving that model (lowest for open-source models like LLaMA-3, higher for frontier models like GPT-4o).
-
R&D / IP Markup is added by proprietary model providers to recover R&D investment.
-
Platform Overhead accounts for features like autoscaling, orchestration, fine-tuning pipelines, and SLAs.
-
Latency / Batch Penalty represents the inefficiency of serving small requests or latency-sensitive applications where batching can’t be maximized.
Importantly, these extra layers reflect strategic choices by providers:
Enterprise customers may accept premium rates in exchange for reliability, compliance, and customer support.
Startups or researchers may optimize batch size and latency tolerance to minimize per-token spend.
Conclusion
Choosing the right AI inference platform is no longer just a technical consideration—it’s a fundamental decision that defines the unit economics and operational scalability of AI-driven businesses. The decision hinges on aligning platform choices with your organization’s current stage of AI maturity, performance requirements, budget constraints, and compliance needs. Real-world inference economics depend critically on optimization strategies, workload characteristics, latency constraints, and model selection—factors best assessed through direct empirical testing. As companies advance along their AI journey, continuously evaluating infrastructure choices and being prepared to transition between platform types will help ensure sustainable growth and long-term competitive advantage in today’s evolving AI landscape.
Footnotes
-
or should shift. Hardware and software lock-in frequently prevent companies from transitioning to a more appropriate inference product. ↩